Since its initial launch, Leanstral has offered an open, practical approach to proof engineering in Lean 4. Today, Mistral AI is releasing Leanstral 1.5, a free Apache-2.0 licensed model with 119B total and only 6B active parameters. This Mixture of Experts (MoE) model delivers a massive performance upgrade that makes formal verification more powerful and accessible than ever.
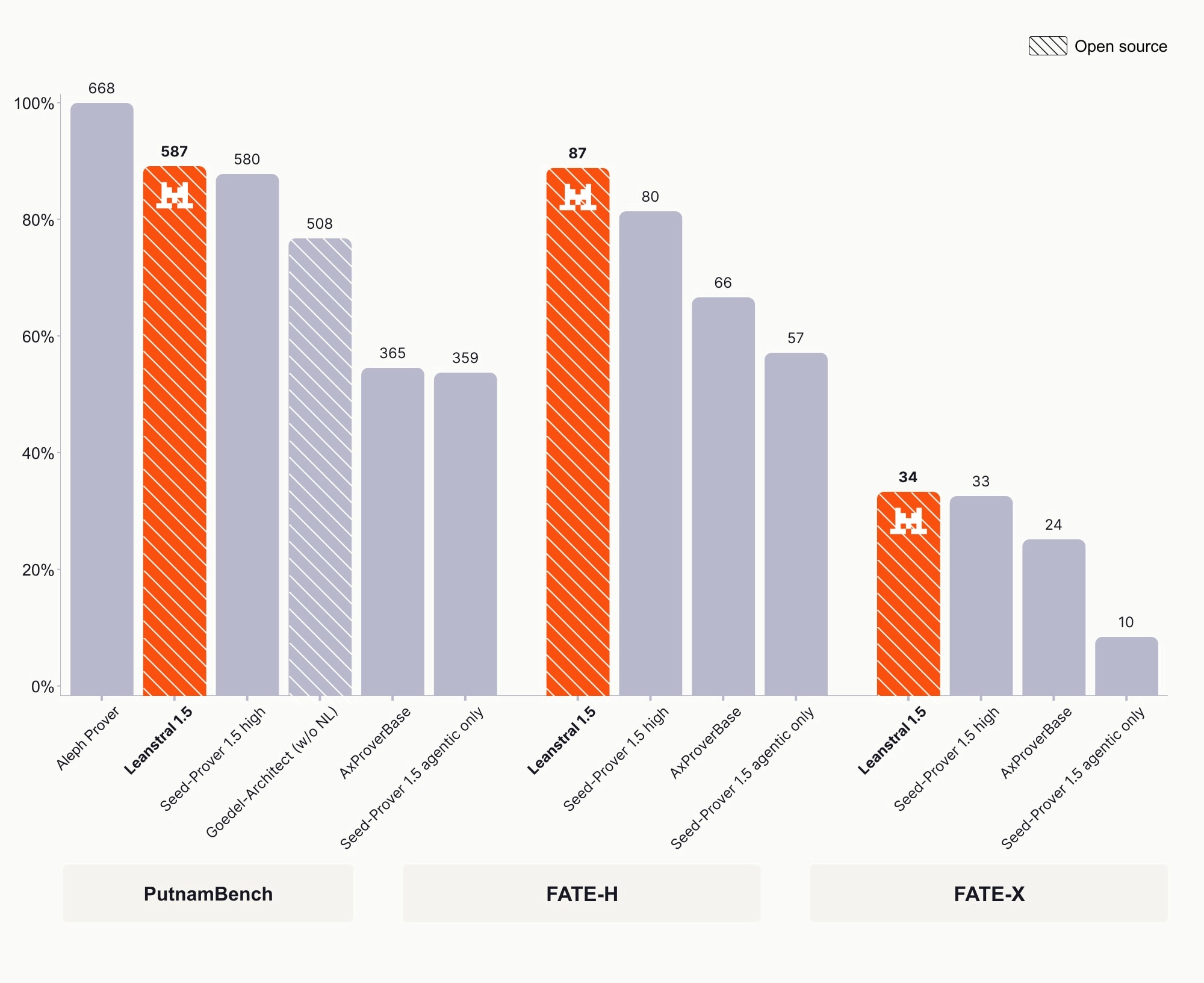
Leanstral 1.5 saturates miniF2F, solves 587/672 PutnamBench problems, and achieves a new state-of-the-art of 87% on FATE-H and 34% on FATE-X. Beyond mathematics benchmarks, it verifies complex code properties and uncovers previously unknown bugs in open-source repositories—proving that rigorous formal methods can be both effective and practical for real-world software engineering.
TL;DR: Quick Reference
Question
Answer
Is Leanstral 1.5 free?
Yes, it is licensed under the open Apache-2.0 license and available via weights or a free API.
What parameters does it use?
It has 119B total parameters, but only 6B active parameters due to its Mixture of Experts (MoE) design.
How is it different from other provers?
It achieves state-of-the-art results at a fraction of the cost ($4/problem vs. $300+ for Seed-Prover 1.5).
Does it support code verification?
Yes, it successfully verified AVL tree time complexity and caught 5 previously unreported bugs in Rust repositories.
What tools does it integrate with?
It integrates with the Lean Language Server Protocol (LSP), Mistral Vibe, and can run in a developer's local terminal.
Training Leanstral 1.5: Multiturn and Agentic Environments
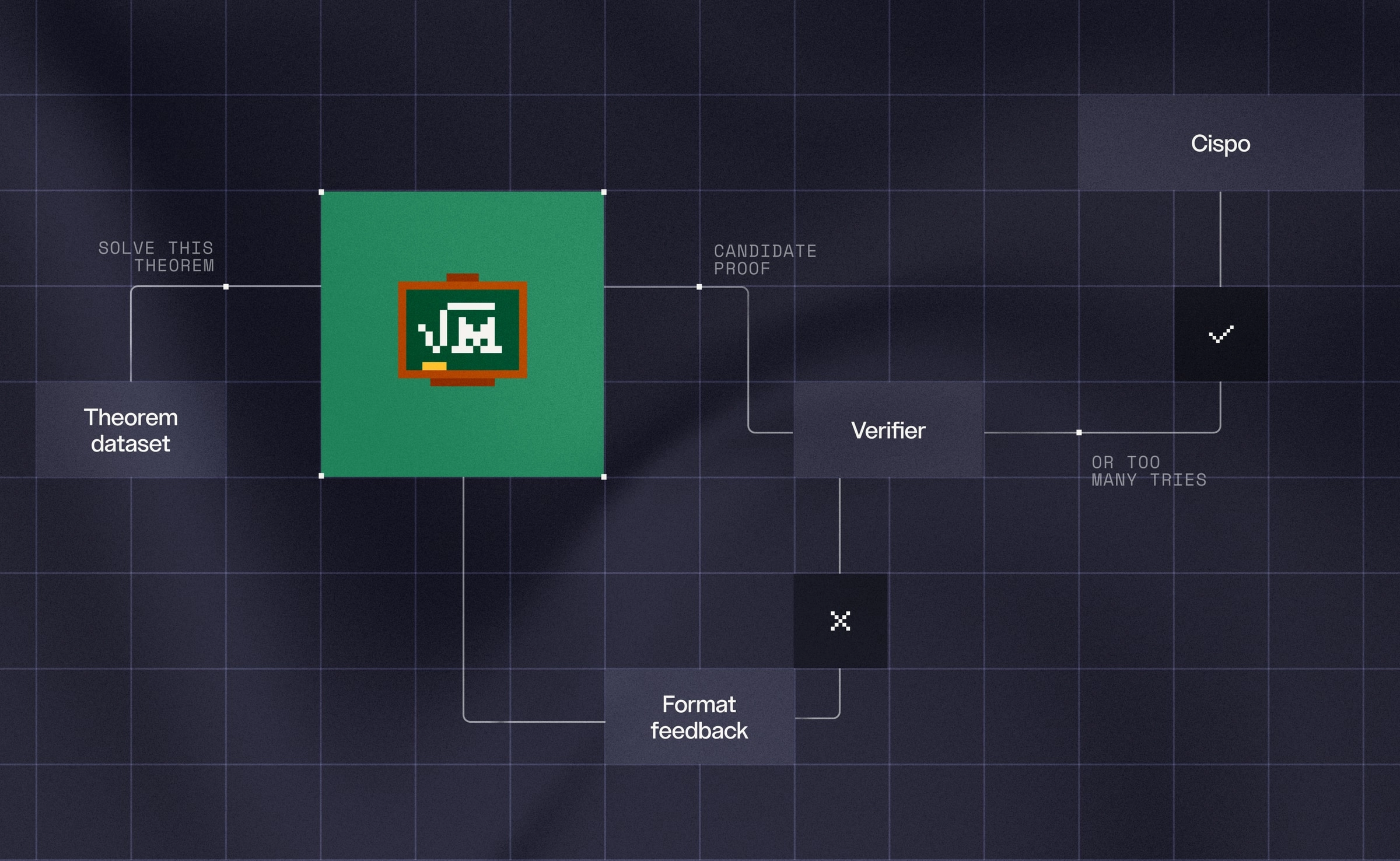
Leanstral 1.5 is trained through a three-stage process: mid-training, supervised fine-tuning (SFT), and reinforcement learning (RL) using CISPO. Much of its strength stems from training on two specialized reinforcement learning environments:
1. The Multiturn Environment
In this setup, the model is given a theorem statement and must either prove or disprove it. The model submits a proof, receives immediate feedback from the Lean compiler, and refines its approach with each attempt. If the proof compiles, it succeeds; otherwise, the loop continues until the model either solves the problem or exhausts its token budget.
2. The Code Agent Environment
In the code agent environment, Leanstral operates like a software developer inside a raw filesystem. It edits files, runs bash commands, and uses the Lean language server to inspect goals, compilation errors, and type information in real time.
This enables the model to tackle long-horizon tasks such as completing partial proofs in a repository, building auxiliary lemmas, and persisting through multiple rounds of context compaction. The entire workflow is verified by a custom fork of SafeVerify for absolute correctness.
Benchmarks and Evaluation
Leanstral 1.5 was evaluated across several key formal mathematics and verification benchmarks, showcasing its test-time scaling properties:
miniF2F: A cross-system benchmark for formal mathematics, ranging from elementary problems to IMO-level challenges. Leanstral 1.5 saturates miniF2F completely, reaching 100% on both the validation and test sets.
PutnamBench: Consists of 672 problems from the Putnam Mathematical Competition, requiring deep reasoning and long proof chains. Leanstral 1.5 solved 587/672 problems.
FATE-H and FATE-X: Abstract algebra benchmarks for graduate and PhD-level problems. Leanstral 1.5 achieved 87% on FATE-H and 34% on FATE-X.
FLTEval: Based on real pull requests from the Fermat’s Last Theorem repository, testing practical proof engineering with real-world complexity.
Strong Test-Time Scaling
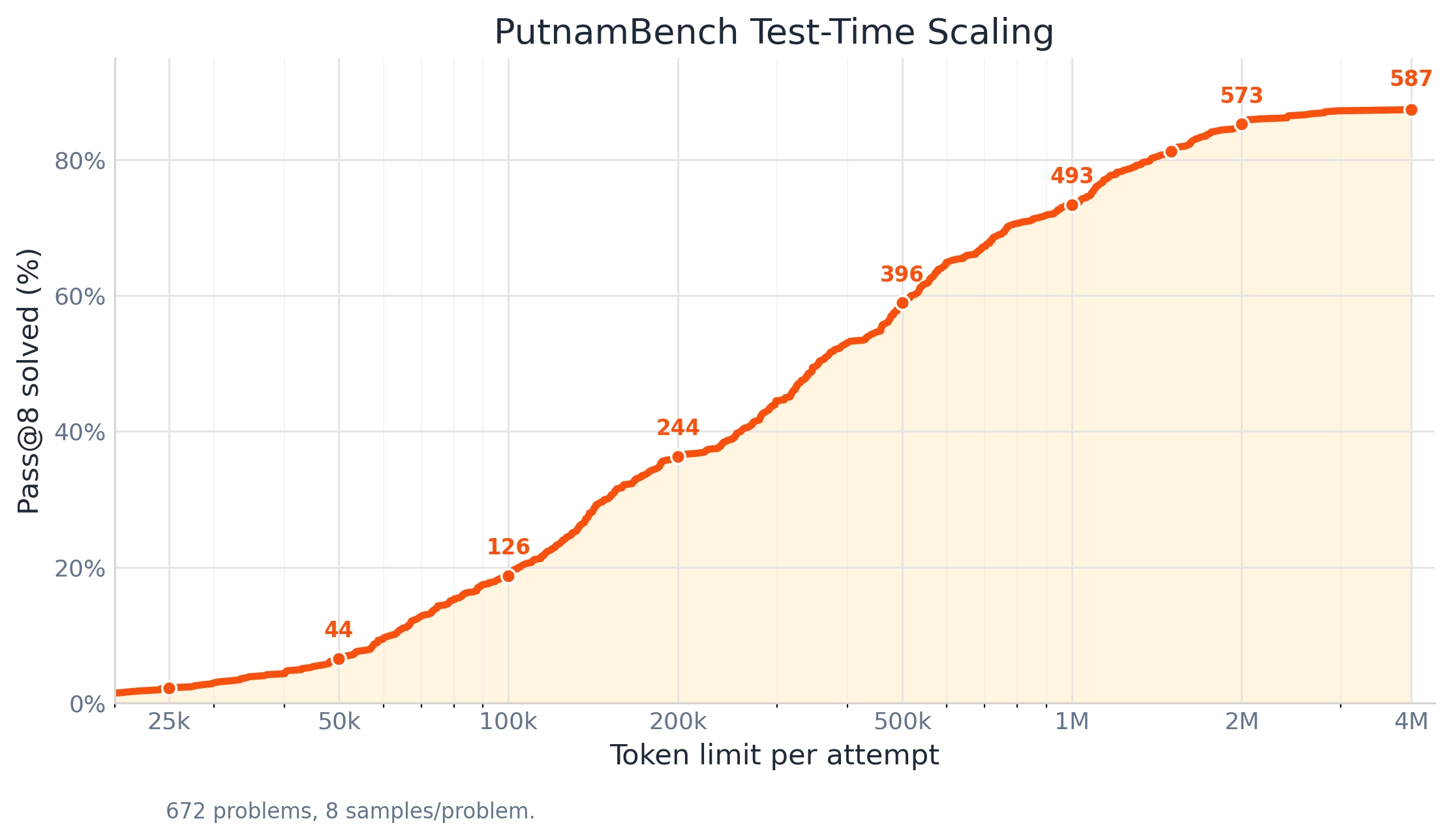
Leanstral 1.5 shows some of the strongest test-time scaling seen in formal reasoning models. When raising the token budget per attempt from 25k to 4M on PutnamBench, performance climbs smoothly and monotonically from 44 problems solved at 50k to 587 solved at 4M tokens.
Rather than giving up when a proof runs long, the model keeps reasoning, editing files, and revising across millions of tokens, turning that compute budget directly into solved problems.
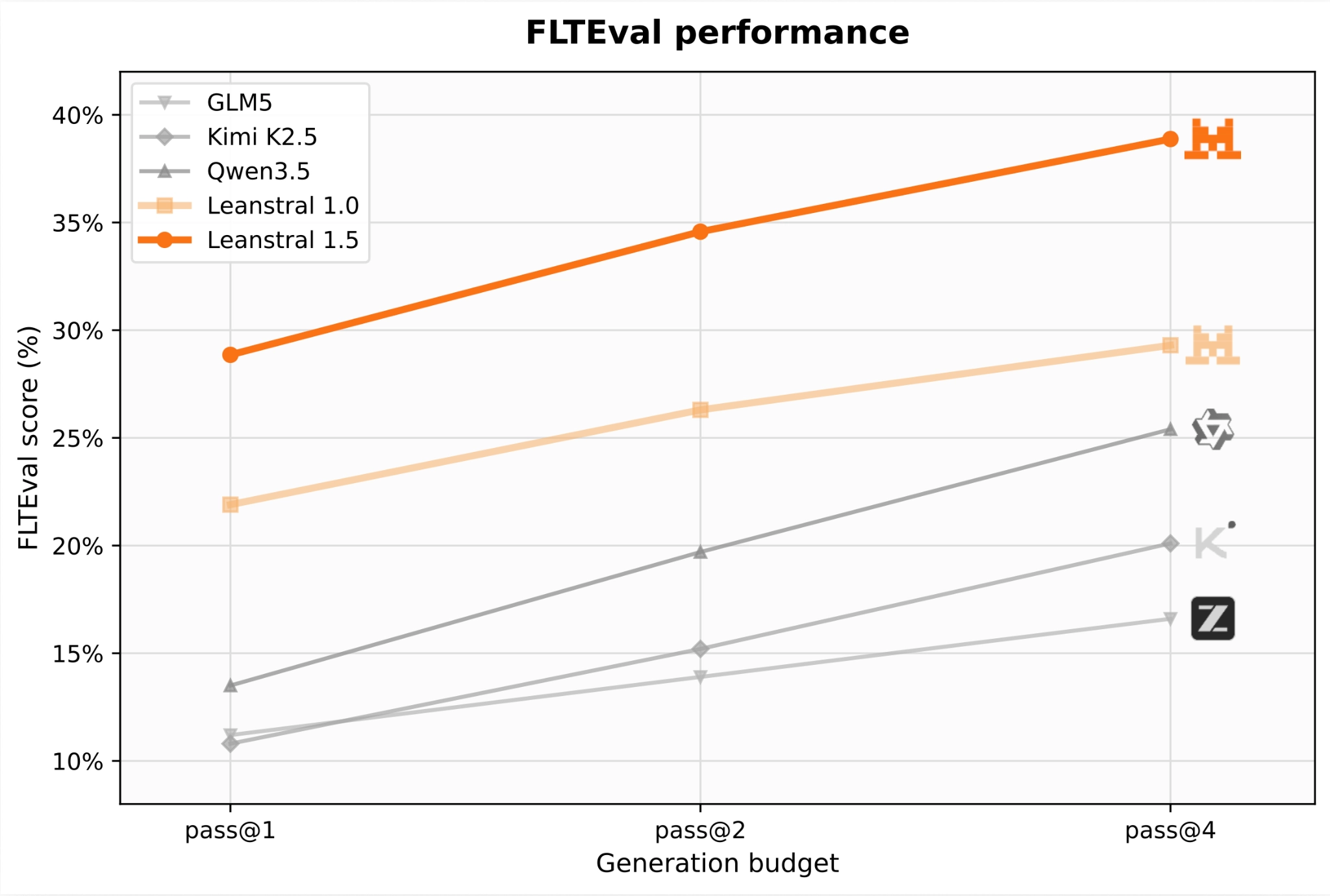
Additionally, Mistral AI has fully open-sourced FLTEval. Leanstral 1.5 lifts Pass@1 on this benchmark from 21.9% to 28.9% and Pass@8 from 31.9% to 43.2%, surpassing much larger models at a fraction of the cost.
Code Verification Case Studies
While primarily trained for mathematics, Leanstral 1.5 exhibits strong capabilities in code verification. Mistral presented two critical case studies demonstrating its impact:
AVL Trees: Proving Time Complexity
AVL trees are self-balancing binary search trees that maintain $O(\log n)$ height through rebalancing during insertions and deletions. Leanstral 1.5 successfully proved these time complexity guarantees for a real implementation. This task required structural induction to mirror the tree’s recursive structure, careful handling of monadic time tracking, and exhaustive case analysis for rebalancing paths.
Over 2.7 million tokens and 22 compactions, the model systematically unfolded each layer of the TimeM monad, exposing the underlying computations despite their interleaving with control flow. It established an almost tight bound of 48 steps per height unit plus a constant for insertion, then connected height to tree size via a logarithmic relationship, delivering complete, verified proofs that insertion and deletion are indeed $O(\log n)$.
Bug Discovery: Finding Hidden Flaws
To test Leanstral’s bug-catching abilities, Mistral built an automated pipeline: Aeneas translates Rust code to Lean, while Leanstral infers the user intent and generates correctness properties from the code. Leanstral then attempts to prove each property.
Across 57 tested repositories, this process flagged 47 violated properties, with 11 pointing to genuine bugs—5 of them previously unreported on GitHub. One such bug was in the sign function for zigzag decoding of the datrs/varinteger library. On input Std.U64.MAX, the expression (value + 1) overflowed, causing crashes in debug mode and silent corruption in release mode. Leanstral’s pipeline caught it automatically, demonstrating that formal verification can find bugs that traditional fuzzing and testing miss.
What People Are Asking: FAQ and Comparisons
How does Leanstral 1.5 compare to Seed-Prover 1.5 or Aleph Prover?
While Seed-Prover 1.5 runs with an massive budget of 10 H20-days per problem (costing an estimated $300+ per run), Leanstral 1.5 solves PutnamBench problems at approximately $4 per problem. Provers ranked higher than Leanstral 1.5 typically operate under different conditions—such as receiving natural-language proof guidance or costing significantly more to run (e.g., Aleph Prover at $54–$68 per problem).
Do I need to pay for API keys to use Leanstral?
No. The model weights are released under the Apache-2.0 license and are free to download on Hugging Face. Additionally, the model is available via a free API endpoint (leanstral-1-5) for developers experimenting with proof automation.
Can I run it locally or in my terminal?
Yes, using Mistral Vibe, you can run agentic proof loops directly inside your repository. Follow the installation steps below to set it up.
Getting Started: Install and Setup
To run Leanstral 1.5 for code verification or mathematics proofs, follow this workflow:
1. Set up Mistral Vibe
Mistral Vibe is the agentic command-line interface for running autonomous loops. Install it using uv:
(Note: If you have no existing MCP servers configured, you may need to remove any empty mcp_servers = [] definitions).
Related reading
Leanstral 1.5 represents a major milestone in making formal verification practical for everyday software development. By reducing proof costs to a fraction of existing systems while improving agentic capabilities in filesystems, it bridges the gap between pure mathematics and code verification.
For more on sovereign open models, document parsing, and agentic workflows, check out these articles on explainx.ai: