



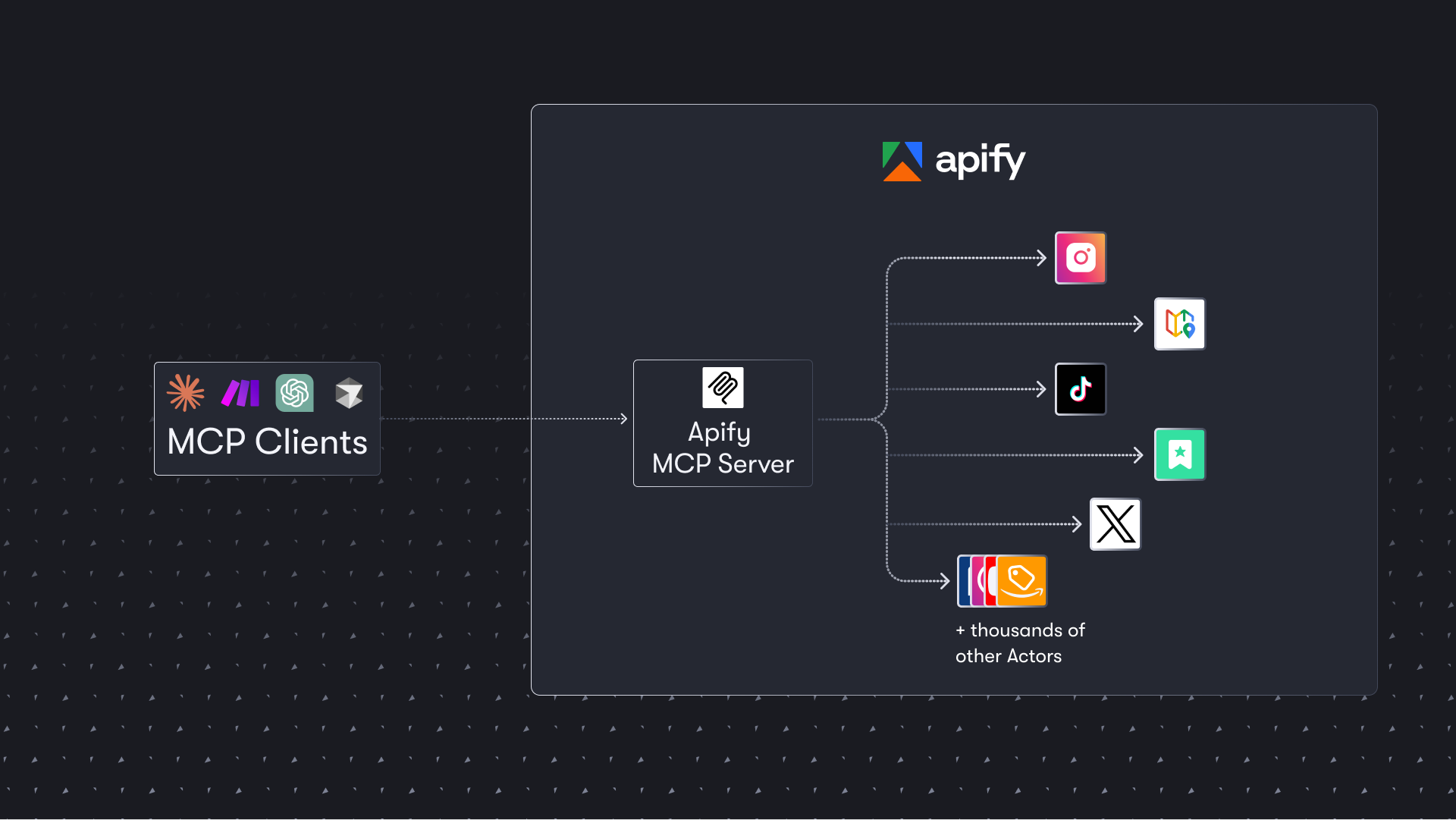
The Apify Model Context Protocol (MCP) server at [**mcp.apify.com**](https://mcp.apify.com) enables your AI agents to extract data from social media, search engines, maps, e-commerce sites, and any other website using thousands of ready-made scrapers, crawlers, and automation tools from the [Apify Store](https://apify.com/store). It supports OAuth, allowing you to connect from clients like Claude.ai or Visual Studio Code using just the URL.
> **🚀 Use the hosted Apify MCP Server!**
>
> For the best experience, connect your AI assistant to our hosted server at **[`https://mcp.apify.com`](https://mcp.apify.com)**. The hosted server supports the latest features - including output schema inference for structured Actor results - that are not available when running locally via stdio.
💰 The server also supports [Skyfire agentic payments](#-skyfire-agentic-payments), allowing AI agents to pay for Actor runs without an API token.
Apify MCP Server is compatible with `Claude Code, Claude.ai, Cursor, VS Code` and any client that adheres to the Model Context Protocol.
Check out the [MCP clients section](#-mcp-clients) for more details or visit the [MCP configuration page](https://mcp.apify.com).
## Table of Contents
- [🌐 Introducing the Apify MCP server](#-introducing-the-apify-mcp-server)
- [🚀 Quickstart](#-quickstart)
- [⚠️ SSE transport deprecation](#%EF%B8%8F-sse-transport-deprecation)
- [🤖 MCP clients](#-mcp-clients)
- [🪄 Try Apify MCP instantly](#-try-apify-mcp-instantly)
- [💰 Skyfire agentic payments](#-skyfire-agentic-payments)
- [🛠️ Tools, resources, and prompts](#%EF%B8%8F-tools-resources-and-prompts)
- [📊 Telemetry](#-telemetry)
- [🐛 Troubleshooting (local MCP server)](#-troubleshooting-local-mcp-server)
- [⚙️ Development](#%EF%B8%8F-development)
- [🤝 Contributing](#-contributing)
- [📚 Learn more](#-learn-more)
# 🌐 Introducing the Apify MCP server
The Apify MCP Server allows an AI assistant to use any [Apify Actor](https://apify.com/store) as a tool to perform a specific task.
For example, it can:
- Use [Facebook Posts Scraper](https://apify.com/apify/facebook-posts-scraper) to extract data from Facebook posts from multiple pages/profiles.
- Use [Google Maps Email Extractor](https://apify.com/lukaskrivka/google-maps-with-contact-details) to extract contact details from Google Maps.
- Use [Google Search Results Scraper](https://apify.com/apify/google-search-scraper) to scrape Google Search Engine Results Pages (SERPs).
- Use [Instagram Scraper](https://apify.com/apify/instagram-scraper) to scrape Instagram posts, profiles, places, photos, and comments.
- Use [RAG Web Browser](https://apify.com/apify/web-scraper) to search the web, scrape the top N URLs, and return their content.
**Video tutorial: Integrate 8,000+ Apify Actors and Agents with Claude**
[](https://www.youtube.com/watch?v=BKu8H91uCTg)
# 🚀 Quickstart
You can use the Apify MCP Server in two ways:
**HTTPS Endpoint (mcp.apify.com)**: Connect from your MCP client via OAuth or by including the `Authorization: Bearer
` header in your requests. This is the recommended method for most use cases. Because it supports OAuth, you can connect from clients like [Claude.ai](https://claude.ai) or [Visual Studio Code](https://code.visualstudio.com/) using just the URL: `https://mcp.apify.com`.
- `https://mcp.apify.com` streamable transport
**Standard Input/Output (stdio)**: Ideal for local integrations and command-line tools like the Claude for Desktop client.
- Set the MCP client server command to `npx @apify/actors-mcp-server` and the `APIFY_TOKEN` environment variable to your Apify API token.
- See `npx @apify/actors-mcp-server --help` for more options.
You can find detailed instructions for setting up the MCP server in the [Apify documentation](https://docs.apify.com/platform/integrations/mcp).
# ⚠️ SSE transport deprecation on April 1, 2026
Update your MCP client config before April 1, 2026.
The Apify MCP server is dropping Server-Sent Events (SSE) transport in favor of Streamable HTTP, in line with the official MCP spec.
Go to [mcp.apify.com](https://mcp.apify.com/) to update the installation for your client of choice, with a valid endpoint.
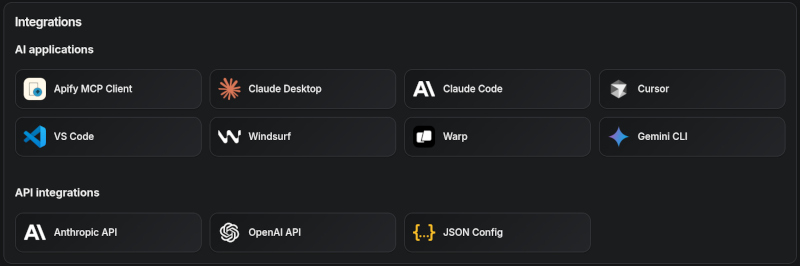
# 🤖 MCP clients
Apify MCP Server is compatible with any MCP client that adheres to the [Model Context Protocol](https://modelcontextprotocol.org/), but the level of support for dynamic tool discovery and other features may vary between clients.
To interact with the Apify MCP server, you can use clients such as: [Claude Desktop](https://claude.ai/download), [Visual Studio Code](https://code.visualstudio.com/), or [Apify Tester MCP Client](https://apify.com/jiri.spilka/tester-mcp-client).
Visit [mcp.apify.com](https://mcp.apify.com) to configure the server for your preferred client.
### Supported clients matrix
The following table outlines the tested MCP clients and their level of support for key features.
| Client | Dynamic Tool Discovery | Notes |
|-----------------------------|------------------------|------------------------------------------------------|
| **Claude.ai (web)** | 🟡 Partial | Tools mey need to be reloaded manually in the client |
| **Claude Desktop** | 🟡 Partial | Tools may need to be reloaded manually in the client |
| **VS Code (Genie)** | ✅ Full | |
| **Cursor** | ✅ Full | |
| **Apify Tester MCP Client** | ✅ Full | Designed for testing Apify MCP servers |
| **OpenCode** | ✅ Full | |
**Smart tool selection based on client capabilities:**
When the `actors` tool category is requested, the server intelligently selects the most appropriate Actor-related tools based on the client's capabilities:
- **Clients with dynamic tool support** (e.g., Claude.ai web, VS Code Genie): The server provides the `add-actor` tool instead of `call-actor`. This allows for a better user experience where users can dynamically discover and add new Actors as tools during their conversation.
- **Clients with limited dynamic tool support** (e.g., Claude Desktop): The server provides the standard `call-actor` tool along with other Actor category tools, ensuring compatibility while maintaining functionality.
# 🪄 Try Apify MCP instantly
Want to try Apify MCP without any setup?
Check out [Apify Tester MCP Client](https://apify.com/jiri.spilka/tester-mcp-client)
This interactive, chat-like interface provides an easy way to explore the capabilities of Apify MCP without any local setup.
Just sign in with your Apify account and start experimenting with web scraping, data extraction, and automation tools!
Or use the MCP bundle file (formerly known as Anthropic Desktop extension file, or DXT) for one-click installation: [Apify MCP server MCPB file](https://github.com/apify/apify-mcp-server/releases/latest/download/apify-mcp-server.mcpb)
# 💰 Skyfire agentic payments
The Apify MCP Server integrates with [Skyfire](https://www.skyfire.xyz/) to enable agentic payments - AI agents can autonomously pay for Actor runs without requiring an Apify API token. Instead of authenticating with `APIFY_TOKEN`, the agent uses Skyfire PAY tokens to cover billing for each tool call.
**Prerequisites:**
- A [Skyfire account](https://www.skyfire.xyz/) with a funded wallet
- An MCP client that supports multiple servers (e.g., Claude Desktop, OpenCode, VS Code)
**Setup:**
Configure both the Skyfire MCP server and the Apify MCP server in your MCP client. Enable payment mode by adding the `payment=skyfire` query parameter to the Apify server URL:
```json
{
"mcpServers": {
"skyfire":
--- 