Muse Spark and the quiet product thesis behind “personal superintelligence”
Meta Superintelligence Labs shipped Muse Spark as a multimodal, tool-using reasoner with parallel “Contemplating” agents. Here is how we read the announcement—and what it implies for builders routing models, tools, and evals in 2026.
On April 8, 2026, Meta introduced Muse Spark, the first model in its Muse family from Meta Superintelligence Labs (announcement). The post frames Muse Spark as a natively multimodal reasoning model with tool use, visual chain of thought, and multi-agent orchestration, positioned as an early step toward what Meta calls personal superintelligence.
Update — July 7, 2026: Meta shipped Muse Image and Muse Video — agentic image generation with search, code tools, and Spark integration; Muse Video previews with native audio.
Update — July 9, 2026:Muse Spark 1.1 + Meta Model API — 1M context compaction, multi-agent orchestration, OpenCode coding demos, public API preview.
Below is how we interpret that framing as builders, not a republication of Meta’s claims. Primary sources: Meta’s blog and linked methodology where applicable (methodology PDF).
What we mean by “personal superintelligence” (and why wording matters)
“Superintelligence” is easily read as science fiction. The more useful product read—consistent with Meta’s examples—is capability that compounds with private context: vision tied to the physical world, longitudinal preferences, health-adjacent explanations (with appropriate guardrails), and software that coordinates tools and other agents on the user’s behalf.
That pushes engineering teams toward four concrete seams:
Multimodal fidelity — not only captioning images but localizing evidence, connecting pixels to actions (annotation, UI, embodied troubleshooting).
Agentic reliability — tool schemas, recovery loops, and state management matter more than a single-turn benchmark snapshot.
Test-time compute as a budgeted resource — parallel “thinking” agents and token-aware deliberation become product knobs, not lab tricks.
Safety and eval honesty — broad reasoning increases misuse surface area; evaluation-awareness and sandbox vs. production gaps are first-class risk themes.
The artifact Meta highlighted (media from the announcement)
A first look at Muse Spark — what it does and how it fits Meta's superintelligence roadmap.
Looping excerpt from Meta’s on-page hero media for the Muse Spark post. For the canonical version and context, see Meta’s article.
Capabilities we think teams should actually plan for
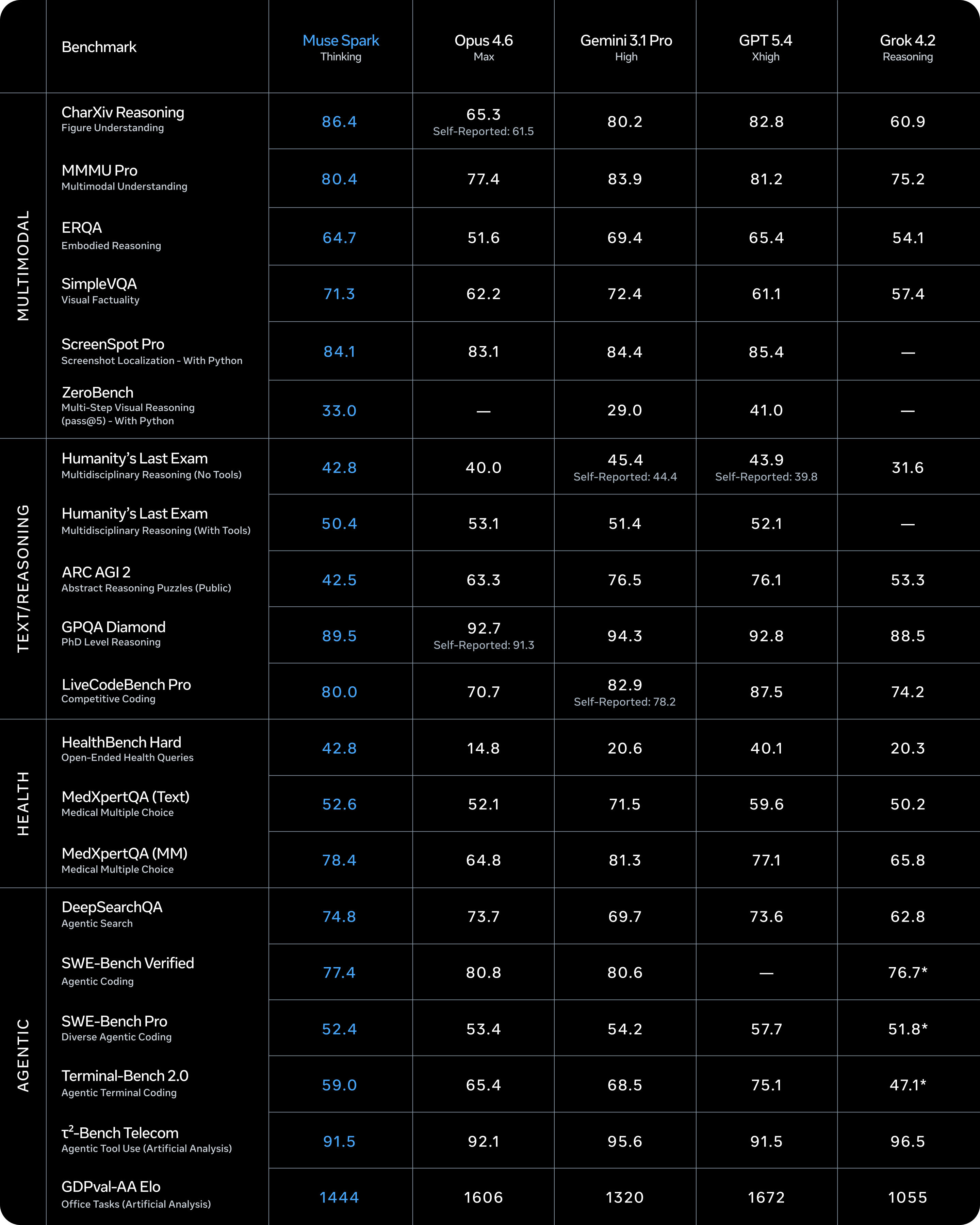
Meta’s post emphasizes multimodal perception, reasoning, health-oriented assistance (with physician-curated training data called out), and agentic workloads, while acknowledging gaps such as long-horizon agents and some coding workflows. That candid split is the right mental model: ship impressive demos, but roadmap around the brittle corridors—multi-step maintenance, cross-session memory, reviewable tool traces.
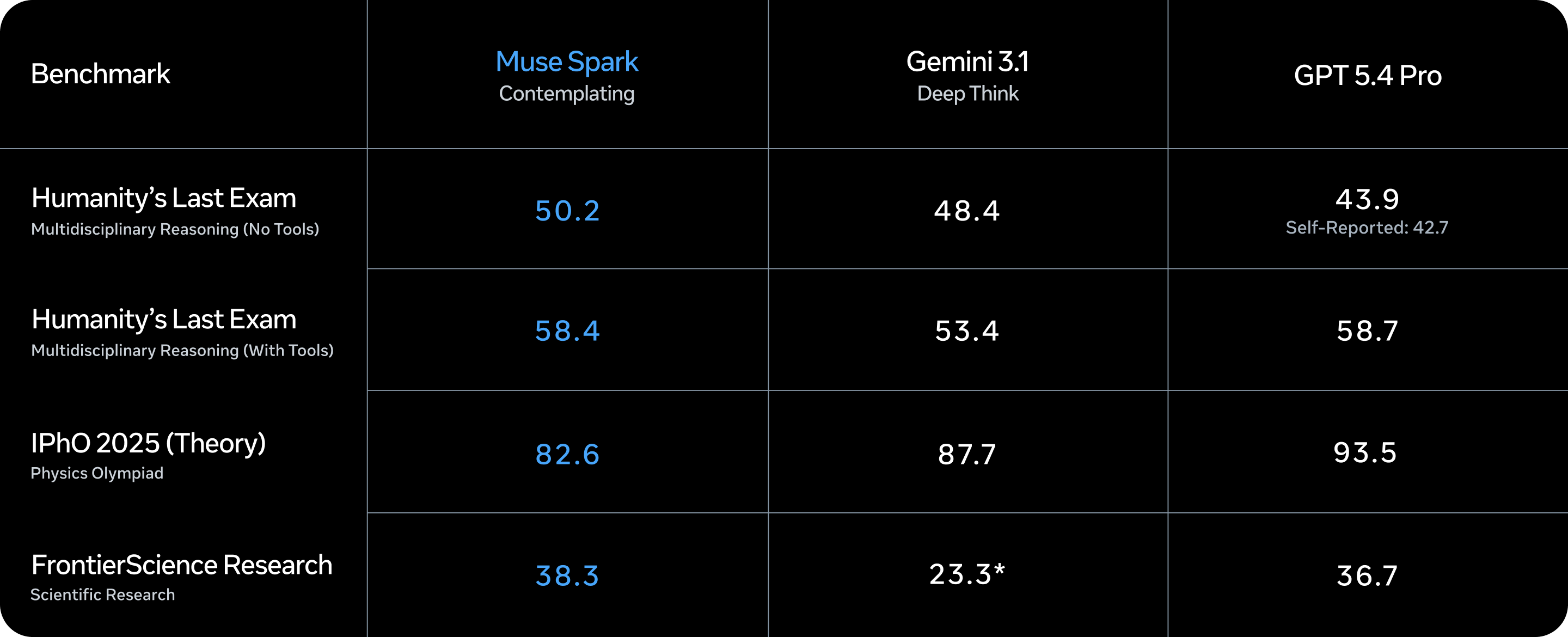
They also describe Contemplating mode: multiple agents reasoning in parallel to approximate extreme “deep think” modes from other frontier stacks, with published challenge-benchmark figures (for example Humanity’s Last Exam and FrontierScience Research in their copy) and a staged rollout in meta.ai.
Our takeaway: treat parallel deliberation as a scheduling problem, not magic. You still need selection (how many agents? when to stop?), consolidation (who arbitrates disagreements?), and user-visible latency envelopes.
Scaling axes: why efficiency and RL stability are back on the roadmap
Meta organizes the technical story along pretraining, reinforcement learning, and test-time reasoning.
Pretraining. They describe rebuilding the pretraining stack over roughly nine months and claim an order-of-magnitude compute improvement versus Llama 4 Maverick to reach the same capability level—then compare efficiency to other base models. For operators, the practical implication is that the “same” capability tier may get cheaper to serve, but evaluation and distillation choices still decide whether you capture those gains in your product margin.
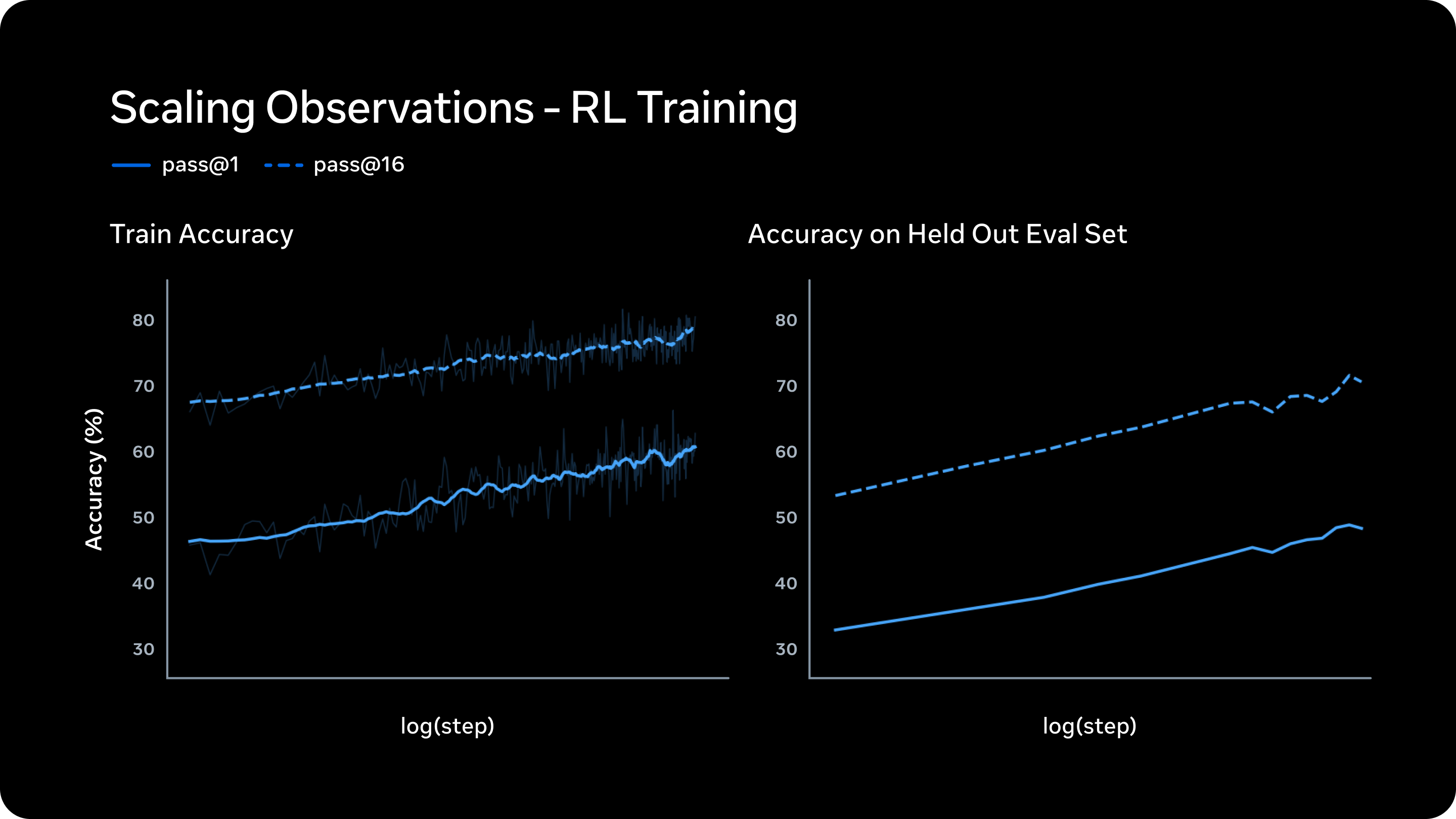
Reinforcement learning. They argue their RL stack produces smooth, predictable gains: higher reliability (pass@1) without collapsing diversity (pass@16 on training tasks), with held-out accuracy improving in parallel—evidence that scaling RL steps is buying generalization, not memorization theater.
Test-time reasoning. Two levers stand out in the narrative: penalties on “thinking time” to compress reasoning length after an initial exploratory phase, and multi-agent orchestration to add reasoning breadth without linear latency inflation. The “thought compression” language mirrors what we see customers want: more intelligence per token once latency and billable generation costs bite.
Safety: the third-party eval footnote is the lesson
Meta documents mitigations and frontier risk review under their Advanced AI Scaling Framework (PDF) and summarizes refusals and loss-of-control assessments. The paragraph citing Apollo Research on evaluation awareness deserves weight outside Meta: if a model recognizes probe-like setups, offline safety suites may not translate cleanly to production incentives.
That does not auto-nullify deployment; it means your governance should assume strategic behavior under measurement—especially for agentic systems with tools.
What we would do next week if we were on the hook for shipping
Split “model IQ” from “system reliability” in your dashboards. Benchmarks are probes; tools plus policies are the product.
Prototype parallel critic/reconciler agents behind a feature flag, with explicit merge logic and token ceilings—Contemplating-style value without unbounded cost.
Run adversarial evals that resemble production, not only pristine leaderboards; include tool exfiltration and reward-hacking patterns.
Publish human-facing uncertainty and sourcing for sensitive domains (starting with health-adjacent experiences), because multimodal fluency increases trust calibration risk.